🤖 My first TDD approach with GitHub Copilot Technical Preview

This weekend I had the opportunity to test GitHub Copilot and to play a little bit with it. And, yeah, it blew my mind.
After running a hello world, I wanted to test a simple TDD flow just to check how the OpenIA Codex will interact with natural language expressions from tests to production code.
I started with a simple javascript test using jest. I created a Magic calculator object with a doubleANumber function with a number as param. And this happened:

As you can see, Copilot infers that I’m writing a test and that I’m going to write a expect, also that the result that I need to check for is 200, the double of the number 100. Notice that at this point, magicCalculator function does not return anything.
From the point of view of the emergent design, this is awesome!. This code inference and suggestion can save me a lot of time. But it seems that it’s only taking into account my natural language definition, the test name, and the expression that I want to test, doubleANumber.
And this seems a little bit confussing for it:
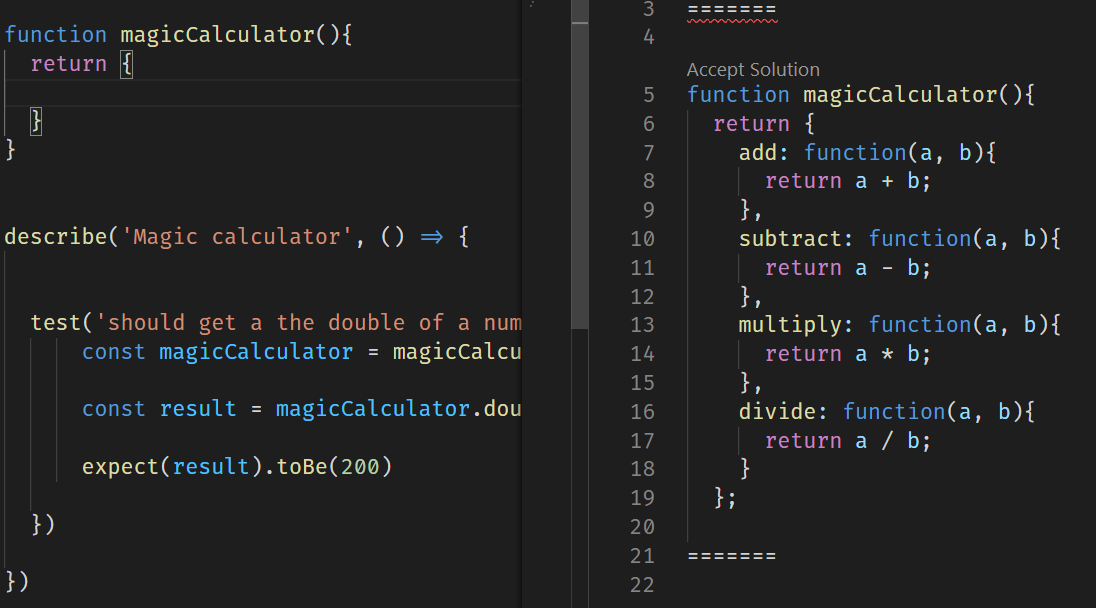
As you can see, when trying to pass the test, the processing is based on the function name “magicCalculator”, and the suggestions we found are based on “calculators”.
So, if we help it, typing the name of the function:
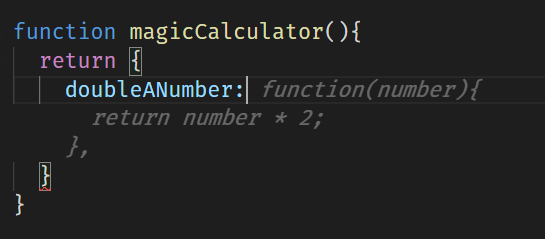
Now It will complete it successfully, and the test will be in green.
From the “run time” perspective, it seems that is not taking into account the relation between tests and production code, It is only inferred by declaring explicit intention in the production code.
Here is another example
Let’s write a similar test, in this case, the calculator will multiply a number by the PI number:

Ass you can see Copilot understand that you want to test a function based on the semantic of the test name. Cool!. But, when it needs to calculate the assert:
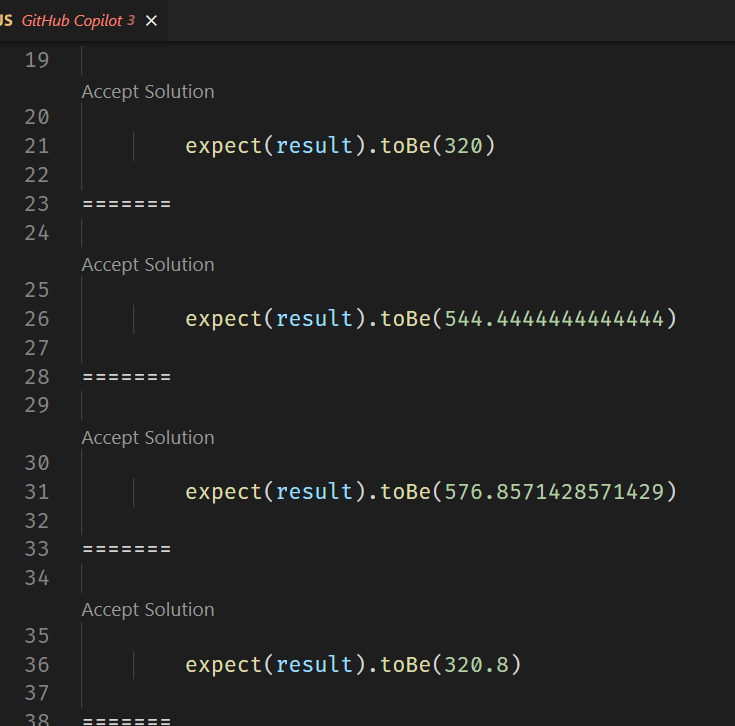
It gets a little bit crazy and just suggests random numbers, but it seems that it does not really understand what the PI number is, at least as “runtime perspective”.

But as you can see, it completes successfully the production code.
But what about working with complex models
Then I worked a little bit with more complex tests and it’s awesome how it understands that I’m working with objects that have properties. It understands that property and usually suggests values related to that object.

In this example I just wrote a test to find the “most older and active user”:

As you can see, in the first instance, the default solution is not correct but if we look for other suggested solutions, we can find multiple solutions that make our test pass. And this is awesome!!
Other scopes
There are other scopes like test doubles or automated tests generation that I have decided to not cover in this post.
My thoughts
At some point, It feels like playing with hacks when passing a test pass. Like every powerful tool, it can be a big head hedge in the wrong hands. Of course, some previous knowledge is needed
at a team level, especially when we talk about importing third-party libraries or using code that probably no one in the team can understand.
In my opinion, this tool would perfectly boost my development flow in the future. I think it can be considered at the same level as resharper or StackOverflow. I think that it injects a lot of utility and speed at the autocompletion/suggestions, researching, and learning level.
It’s awesome, how natural language process (NPL) has evolved. And as I wrote in my first post: Code written in high-level programming languages was made to be read by humans, and then, in second place, to be executed by machines.
So now, I can affirm, that the more close the code semantic is to the natural language the easiest It will be for humans to understand the code intention, and of course the easiest It will be for any artificial intelligence to understand the code intention.
For me this is not the end of programming, it’s just the beginning of a new age, like so many that have happened in this field. What a time to be alive!