⚡ Azure Cosmos DB filter by multiple IDs performance comparison:

Some days ago we were designing a new feature using Azure Cosmos DB. We needed to query data filtering by 4 different IDs. After comparing a few options, we ended up wondering: What is the most efficient way to query this data?
The answer to that question, in computer science should be simple: “direct access” O(1). But, when dealing with multiple IDs at the same time, this is not always trivial. So we decided to benchmark a few different options.
How Cosmos DB Data is distributed
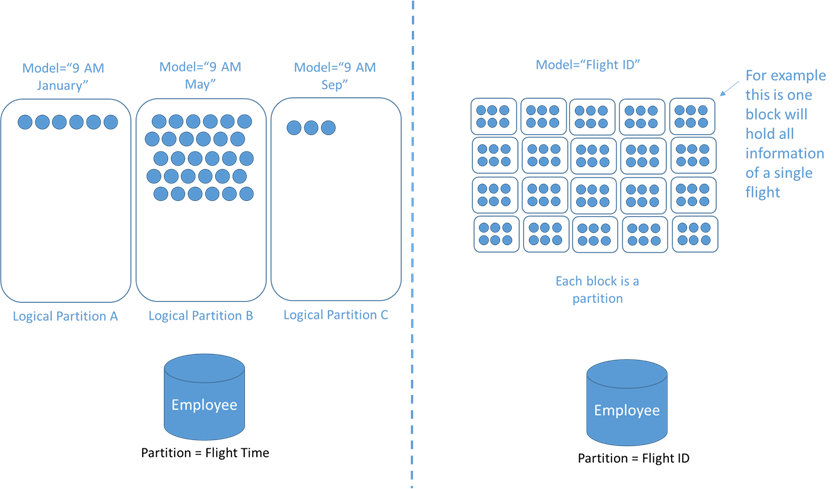
- Data is stored in Containers and partitioned using a partition-key.
- A partition-key consists in two parts: partition-key path and the partition-key value.
- Partition-key path is defined during Container creation.
- In NoSQL API, data entries are called Items.
- Partition-key value is defined during Item insertion.
- Logial partitions are a group of items with the same partition-key value.
- Physical partitions are managed by Azure Cosmos DB under the hood, based on load and amount of data. Internally, one or more logical partitions are mapped to a single physical partition.
- Depending on which partition-key property path we select, we will have a more or less balanced data storage and data load across partitions. This will depend on the distribution of the values. For more info:
Partition-key value and "{Item id}" can be the same value. This will cause that: “Millions of customers would result in millions of logical partitions”, and is perfectly fine.
How index works in Cosmos DB
When storing documents in Cosmos db, document data is indexed, according to the indexing policy of the container. Azure Cosmos DB uses a tree representation for the data based on a sorted ascendent inverted index data structure.
Depending on the clauses used in the query, the query engine can utilize the inverted index in five different ways with different performance and cost(Index lookup):
- Index Seek (Equality filters, IN)
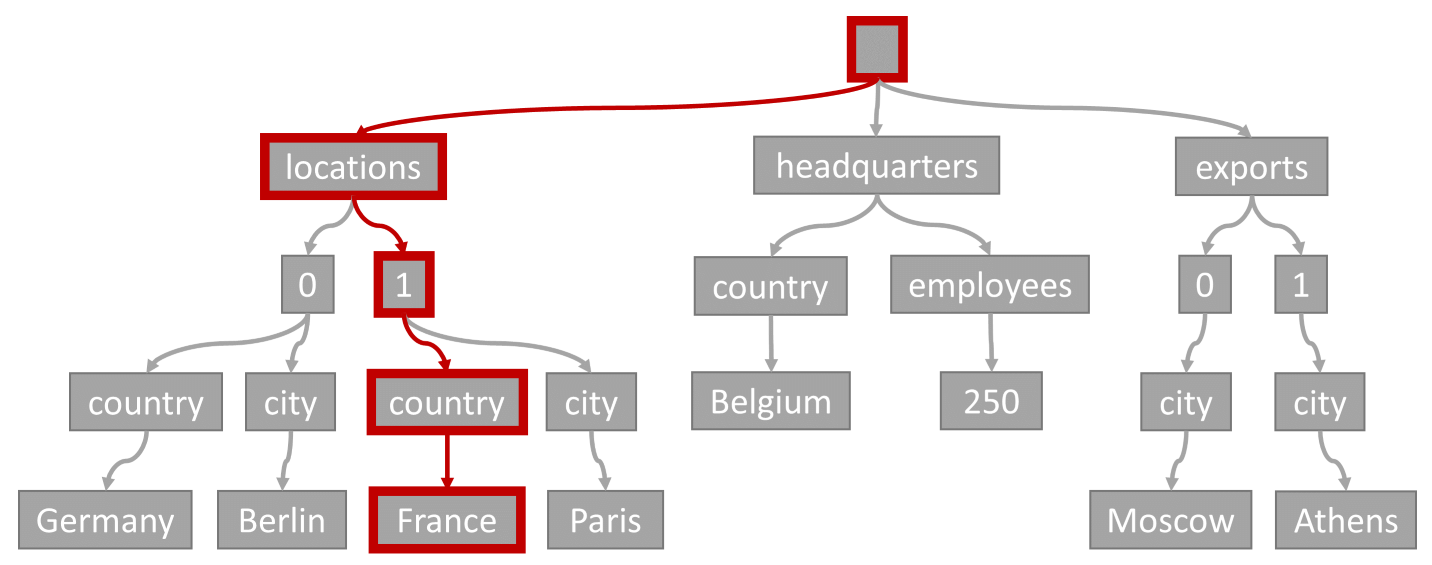
- Precise index scan (Range comparisons (>, <, <=, or >=), StartsWith)
- Expanded index scan (StartsWith (case-insensitive), StringEquals (case-insensitive))
- Full index scan (Contains, EndsWith, RegexMatch, LIKE)
- Full scan (Upper, Lower, Avg, Count, Max, Min, Sum)
How queries are executed in Azure Cosmos DB
To maximize the advantage of the optimizations during the query execution pipeline, and to predict unexpected costs, we should understand that the SDK performs these logical steps:
- Parse the SQL query to determine the query execution plan.
- If the query includes a filter against the partition key it’s routed to a single partition. If not, the result is the merge of results from all the executions in all partitions.
- The query is executed within each partition in series or parallel depending on the configuration. Each partition takes one or more rounds depending on query complexity, page size, or provisioned throughput.
- The SDK performs a summarization of the query results across partitions.
Option 1: Using Cosmos DB NoSQL property indexing tree
According to the Cosmos DB indexing theory data should be indexed inside a container by path levels, in this case:
- Item level: using
"{ProductId}"and containing multiple tenants. - Tenant level: using
"{TenantId}"and containing multiple users. - User level: using
"{UserId}"and containing multiple sessions. - Session level: using
"{SessionId}"and containing some Data.
{
"id": "b79bd870-a752-4457-81b0-550af9e6b2c8",
"tenants": [{
"TenantId": "a02054b8-7ddd-46b6-a855-4408f469be11",
"users": [{
"UserId": "962504d8-d434-4a57-b90b-d521a381e6e6",
"sessions": [{
"SessionId": "944c3e84-8c31-4593-a6e8-568ca7c39cc4",
"Data": "417c1bb5-6549-493d-b72e-8a30c3b52e79"
}]
}]
}]
}So, queries should filter by the 4 levels:
SELECT
c.id,
t.TenantId,
u.UserId,
s.SessionId,
s.Data
FROM
c
JOIN
t IN c.tenants
JOIN
u IN t.users
JOIN
s IN u.sessions
WHERE
c.id = 'b79bd870-a752-4457-81b0-550af9e6b2c8'
AND t.TenantId = 'a02054b8-7ddd-46b6-a855-4408f469be11'
AND u.UserId = '962504d8-d434-4a57-b90b-d521a381e6e6'
AND s.SessionId = '944c3e84-8c31-4593-a6e8-568ca7c39cc4'Option 2: Concatenate three IDS into a single ID and then search by 2 only IDs.
The idea behind this approach is to reduce the number of where clauses in the query and the number of levels in order to improve the performance. So We will have only 2 IDs:
- Item level:
"{ProductId}" - TenantUserAndSession level: A string concat
"{TenantId}-{UserId}-{SessionId}", and some Data
{
"id": "b79bd870-a752-4457-81b0-550af9e6b2c8",
"Rows": [{
"TenantUserAndSessionId": "a02054b8-7ddd-46b6-a855-4408f469be11-962504d8-d434-4a57-b90b-d521a381e6e6-944c3e84-8c31-4593-a6e8-568ca7c39cc4",
"Data": "417c1bb5-6549-493d-b72e-8a30c3b52e79"
}]
}Queries should filter by the 2 IDs like:
SELECT
c.id,
t.TenantUserAndSessionId,
t.Data
FROM
c
JOIN
t IN c.Rows
WHERE
c.id = 'aaeab0ff-f000-4745-8a67-b68cddaccc0a'
AND t.TenantUserAndSessionId = 'b01fedbd-8097-4c5e-9760-5274c0fa490d-68a90395-2500-4548-8edd-3839145e1d29-99f58b1b-13cf-4430-9d19-f0960347c1e2'Option 3: Concatenate all the Ids and use it as the partition-key
The idea here is to, following Cosmos DB best practices for query performance, “Favor queries with the partition-key value in the filter clause for low latency”. And also try to take advantage of In-partition querys optimizations, to improve performance:
- Product level : A string concat
"{ProductId}-{TenantId}-{UserId}-{SessionId}", and some Data
{
"id": "b79bd870-a752-4457-81b0-550af9e6b2c8-a02054b8-7ddd-46b6-a855-4408f469be11-962504d8-d434-4a57-b90b-d521a381e6e6-944c3e84-8c31-4593-a6e8-568ca7c39cc4",
"Data": "417c1bb5-6549-493d-b72e-8a30c3b52e79"
}Remember that partition-key is a path on the tree. To search by partition in our example we will request data directly ussing ReadItemAsync(id, partitionKey) method, while id = partition-key value. the query will conceptualy look like this:
SELECT
c.id,
c.Data
FROM
c
WHERE
c.id = 'b79bd870-a752-4457-81b0-550af9e6b2c8-a02054b8-7ddd-46b6-a855-4408f469be11-962504d8-d434-4a57-b90b-d521a381e6e6-944c3e84-8c31-4593-a6e8-568ca7c39cc4'Option 4: Use Hierarchical partition-keys
Using Hierarchical partition-keys is only recommended if we need highly scale horizontally across multiple physical partitions. But we wanted to test another option.
{
"id": "b79bd870-a752-4457-81b0-550af9e6b2c8",
"TenantId": "a02054b8-7ddd-46b6-a855-4408f469be11",
"UserId": "962504d8-d434-4a57-b90b-d521a381e6e6",
"SessionId": "944c3e84-8c31-4593-a6e8-568ca7c39cc4",
"Data": "417c1bb5-6549-493d-b72e-8a30c3b52e79"
}To search by partition-key in our example we will request data directly ussing ReadItemAsync(id, partitionKey) method, the query will conceptualy look like this:
SELECT
c.id,
c.TenantId,
c.UserId,
c.SessionId,
c.Data
FROM
c
WHERE
c.id = 'b79bd870-a752-4457-81b0-550af9e6b2c8'
AND c.TenantId = 'a02054b8-7ddd-46b6-a855-4408f469be11'
AND c.UserId = '962504d8-d434-4a57-b90b-d521a381e6e6'
AND c.SessionId = '944c3e84-8c31-4593-a6e8-568ca7c39cc4'Benchmarks Results
In this repo, you can find the automated benchmark tests for comparing speed and client memory allocation, that use BenchmarkDotNet.
For this case, we randomly created 100000 combinations of the 4 IDs (ProductId/ TenantId/UserId/SessionId) and some Data values. Then, we stored them in different containers, one for each option. And finally, we executed the benchmarks running a bunch of 100 random reads for each option:
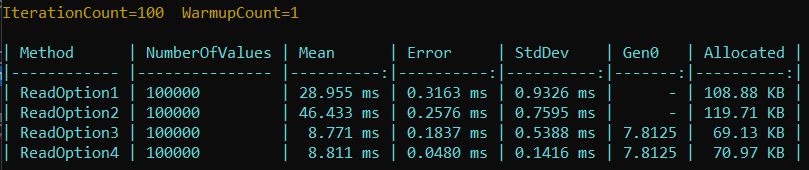
Also, we had compare query performance stats using the query executor stats tab:
Option1 Query Stats
Request Charge 3.58 RUs
Index lookup time 0.11 ms
Document load time 0.15 ms
Query engine execution time 0.030000000000000002 msOption2 Query Stats
Request Charge 5.53 RUs
Index lookup time 0.08 ms
Document load time 0.17 ms
Query engine execution time 0.12000000000000001 msOption3 Query Stats
Request Charge 2.83 RUs
Index lookup time 0.23 ms
Document load time 0.030000000000000002 ms
Query engine execution time 0.01 msOption4 Query Stats
Request Charge 3.13 RUs
Index lookup time 0.7100000000000001 ms
Document load time 0.030000000000000002 ms
Query engine execution time 0.01 ms
Conclusions
In Option1 we use 4 equality filters, so this will result in a Index seek,“ the most efficient way to use the index”, Index lookup over a range index.
In Option2 we are using 2 equality filters. As we can see, the fewer levels we need to go deep in through the tree are not necessarily faster. In this case, this is the worst option because the data is not balanced through the tree, the second level grows in width too much.
The indexing mode is set to consistent by default. This means that some system properties are automatically indexed like the "{Item id}".
The Item id / partition-keys paths looks like:
- Option1: Item id =
"{ProductId}"Partition-key path:/id - Option2: Item id =
"{ProductId}"Partition-key path:/id - Option3: Item id =
"{ProductId}-{TenantId}-{UserId}-{SessionId}"Partition-key path:/id - Option4: Item id =
"{ProductId}"Partition-key path:/TenantId;/UserId;/SessionId;
We can specify a partition-key value with de SDK to access logical partition data directly. This could results in a performance boost in (Option3 and Option4).
When querying data in a distributed system like Cosmos DB, latency enters the game. So if the system is degraded by latency, all options will be affected. For this experiment, we will test only against one single physical partition, for all options.
Querying data by Partition-key, Option3, and hierarchical partition-keys, Option4, can reduce latency if queries are performed over the same physical partition.
And What about the Write Cost?
In all options we are using CosmosDB NoSql, so we need to read and write the entire document for every single write. (Writes RUs is directly related with Reads RUs) .So, more efficient reads result in more efficient writes.
Unlike what happens in a SQL-type database, where the index has been defined before data insertion, in Cosmos DB we are using an inverted index, so the index is created after the insertion, when the engine has analyzed the documents on which the search will be based.
During writes, items inside a container and item’s properties are automatically indexed. This results in extra operation of indexation (more RUs), in order to maintain index consistency.
Option1 and Option2 have a more complex schema inside the item but Option3 and Option4, reindexe the “top level more frequently. So Option3 and Option4 are more “slow” while doing writes. You can test this easily by running the benchmarks example.