🔢 How Many Bits Do Character Encodings Use?

If we look at the Computer History, we can see that since the 1940s, characters have been represented in very different ways.
Writing systems changed everything—more than you think
According to Wikipedia, we call Prehistory the period of human history between the first known use of stone tools by hominins, c. 3.3 million years ago, and the beginning of recorded history with the invention of writing systems.
And YES! That’s it. Until this moment, we unlocked the ability to transmit information that persists through time. Or in other words, our knowledge became immortal.
Breaking the Space-Time Barrier
We have been using many systems to communicate over long distances, including visual methods such as beacons, smoke signals, flag semaphore, and optical telegraphs, as well as messenger systems like homing pigeons.
The next breakthrough that changed everything was Telegraphy. For the first time in history, it enabled the transmission of information at the speed of light.
Morse Code (1-Bit, Not Binary)
In 1865, Morse code became the standard for communications. These systems were able to send and record messages over long distances by pressing a single button, representing dots, dashes, and silences. With this, the code was able to represent 26 letters and 10 numerals.

Notice that with this and a lot of cables, we connected a large part of the world in the 19th century.
Dots and dashes changed the game and conquered the world. But to scale, we needed more human-friendly interfaces that didn’t require knowledge of Morse Code. That’s where teleprinters appeared. A teleprinter is a telegraph machine that can send messages from a typewriter-like keyboard.
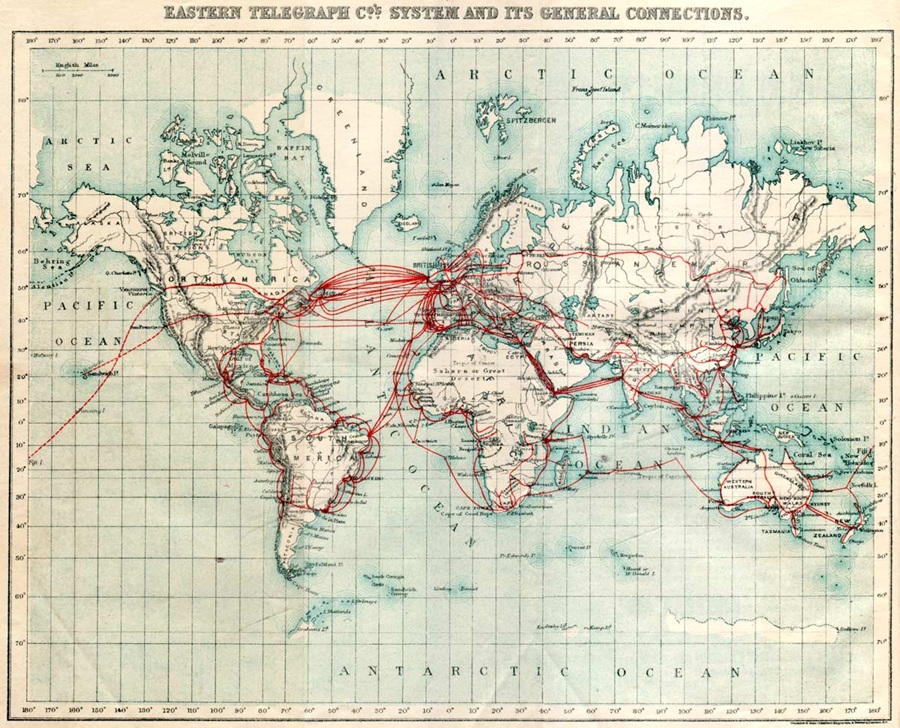
Baudot Code (5-Bit)
In the beginning, teleprinters used the Baudot code, which relied on a five-key keyboard to represent the 26 letters of the basic Latin encoding, known as International Telegraph Alphabet No. 1 (ITA1).
In 1932, ITA2 became the standard for teletypewriters.
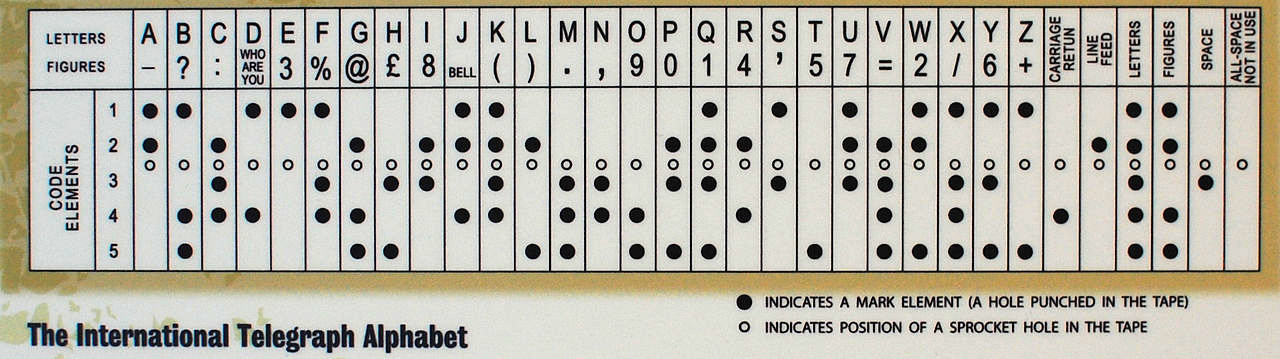
ASCII (7-Bit)
In 1963, the American Standard Code for Information Interchange (ASCII) encoding was created.
ASCII used a 7-bit system, allowing for 128 characters. This included English letters (both uppercase and lowercase), digits, punctuation marks, and control characters (such as newline (LF) and carriage return (CR)).
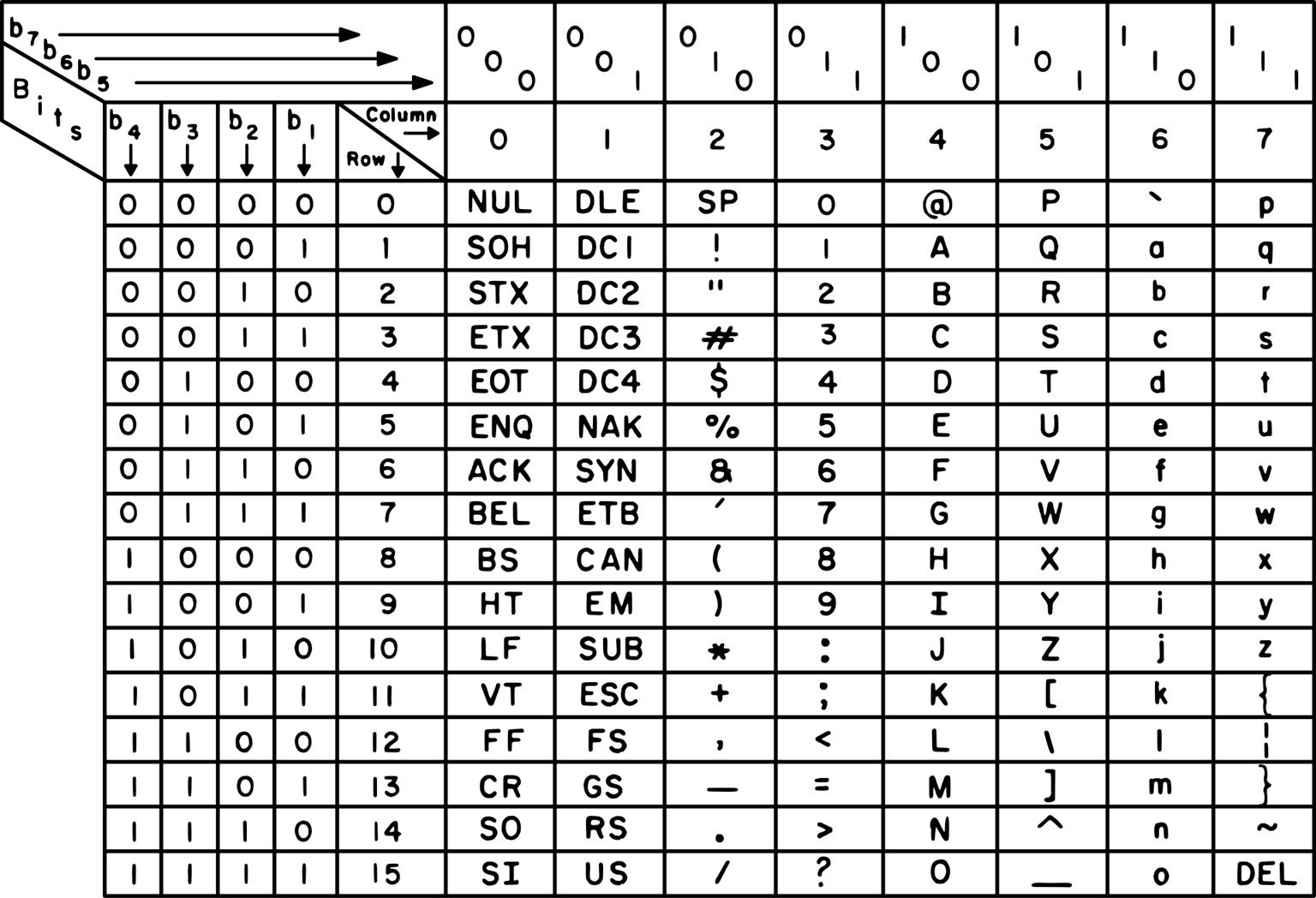
7-bit ASCII was designed for teleprinters. It coexisted with early computers in the 1950s but was replaced by fully electronic computer terminals.
Extended ASCII (8-Bit)
In the 1980s, as computers became more widespread, the need for additional symbols, accented characters (for non-English languages), and graphical symbols led to the development of Extended ASCII. There were multiple Extended ASCII variants (1980s–1990s), for example:
- ISCII for India
- VISCII for Vietnam
- IBM Code Pages (437)
- Atari ATASCII
- Kaypro CP/M for Greek
- PETSCII
- Sharp MZ character set
- DEC-MCS
- Aooke Mac OS Roman
- Adobe PostScript Standard Encoding
- ISO/IEC 8859
- Windows-1252
- KOI8-R for Cyrillic
Unicode, One Encoding to Rule Them All
In the 1990s, as computers began to be used more globally, the need for a character encoding system that could support all languages and scripts became apparent. This led to the development of the Unicode Standard by the Unicode Consortium, founded in 1988 and incorporated in 1991.
- Universal (addressing the needs of world languages)
- Uniform (fixed-width codes for efficient access)
- Unique (each bit sequence has only one interpretation into character codes)
It is a character encoding standard that aims to represent every character from every writing system, including symbols, emoji, and historical characters.
Versions:
Initially, Unicode 1.0 used a 16-bit system, which allowed for 7,129 characters. It quickly became clear that more characters were needed, so Unicode has been extended over the years, for example:
- Version 1.0 (October 1991) - 7,129 Characters
- Version 16.0 (September 2024) - 154,998 Characters
But it’s not that easy. If we stored all numbers as 32-bits, it would take up too much space, wouldn’t it?
UTF
Unicode defines two mapping methods: the Unicode Transformation Format (UTF) encodings and the Universal Coded Character Set (UCS) encodings. An encoding maps (possibly a subset of) the range of Unicode code points to sequences of values in some fixed-size range, termed code units. All UTF encodings map code points to a unique sequence of bytes.
- UTF-8, (1 to 4) 8-bit units per code point (maximal compatibility with ASCII)
- UTF-16, 1 16-bit unit per code point below U+010000, and a surrogate pair of 2 16-bit units per code point in the range U+010000 to U+10FFFF
- UTF-32, which uses 1 32-bit unit per code point
Example U+0041 A
Character A, Latin Capital Letter A, Unicode Number (Unicode Code Point) U+0041, is part of the Basic Latin (Code Block 0000–007F), included in the Uppercase Latin Alphabet Subblock (0041), which is fully compatible with ASCII.
| Encoding | Hex | Dec (Bytes) | Dec | Binary |
|---|---|---|---|---|
| UTF-8 | 41 | 65 | 65 | 01000001 |
| UTF-16BE | 00 41 | 0 65 | 65 | 00000000 01000001 |
| UTF-16LE | 41 00 | 65 0 | 16640 | 01000001 00000000 |
| UTF-32BE | 00 00 00 41 | 0 0 0 65 | 65 | 00000000 00000000 00000000 01000001 |
| UTF-32LE | 41 00 00 00 | 65 0 0 0 | 1090519040 | 01000001 00000000 00000000 00000000 |
Example U+00C1 Á
Character Á, Latin Capital Letter A with Acute Á, Unicode Number (Unicode Code Point) U+00C1, is part of the Latin-1 Supplement (Code Block 0080–00FF), included in the Uppercase Letters Subblock (00D8).
| Encoding | Hex | Dec (Bytes) | Dec | Binary |
|---|---|---|---|---|
| UTF-8 | C3 81 | 195 129 | 50049 | 11000011 10000001 |
| UTF-16BE | 00 C1 | 0 193 | 193 | 00000000 11000001 |
| UTF-16LE | C1 00 | 193 0 | 49408 | 11000001 00000000 |
| UTF-32BE | 00 00 00 C1 | 0 0 0 193 | 193 | 00000000 00000000 00000000 11000001 |
| UTF-32LE | C1 00 00 00 | 193 0 0 0 | 3238002688 | 11000001 00000000 00000000 00000000 |
Example U+1F642 🙂
Character 🙂, Slightly Smiling Face Emoji 🙂, Unicode Number (Unicode Code Point) U+1F642,
is part of the Emoticons (Emoji) (Code Block 1F600–1F64F), included in the Faces Subblock (1F600).
| Encoding | Hex | Dec (Bytes) | Dec | Binary |
|---|---|---|---|---|
| UTF-8 | F0 9F 99 82 | 240 159 153 130 | 4036991362 | 11110000 10011111 10011001 10000010 |
| UTF-16BE | D8 3D DE 42 | 216 61 222 66 | 3627933250 | 11011000 00111101 11011110 01000010 |
| UTF-16LE | 3D D8 42 DE | 61 216 66 222 | 1037583070 | 00111101 11011000 01000010 11011110 |
| UTF-32BE | 00 01 F6 42 | 0 1 246 66 | 128578 | 00000000 00000001 11110110 01000010 |
| UTF-32LE | 42 F6 01 00 | 66 246 1 0 | 1123418368 | 01000010 11110110 00000001 00000000 |
Example U+1F44D + U+1F3FD 👍🏽
Character 👍🏽 is the combination of two Unicode Code Points: 👍 Thumbs Up Emoji U+1F44D and 🏽 Medium Skin Tone Emoji U+1F3FD. It was approved in 2015 as an Emoji in version 1.0 and added to the Closed Hand with Fingers subcategory of the People & Body category.
For example, 👨👩👧👧 Family: Man, Woman, Girl, Girl Emoji is an emoji ligature composed of the Unicode Code Points: U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467. This requires 4 + 2 + 4 + 2 + 4 + 2 + 4 = 22 bytes in the best case (UTF-16) to represent this emoji 🤯.
How many Bits in disk?
UTF-8
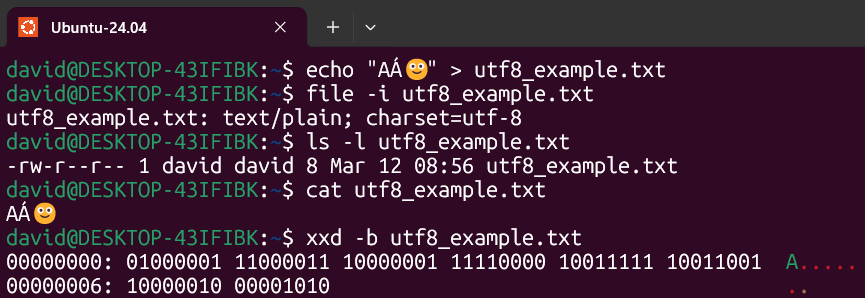
For this example, I will create a file containing the following string:
echo "AÁ🙂" > utf8_example.txtI will check the file encoding, which by default is UTF-8.
file -i utf8_example.txtIf we check the file length, we can see that it is 8 bytes.
ls -l utf8_example.txtI will print the content of the file in the terminal, and since it is UTF-8, it will be displayed without any issues.
cat utf8_example.txtIf we examine the binary data of the file, we will see the following:
xxd -b utf8_example.txt| Character | Bytes | Binary Representation |
|---|---|---|
| A | 1 | 01000001 |
| Á | 2 | 11000011 10000001 |
| 🙂 | 4 | 11110000 10011111 10011001 10000010 |
| LF (Line Feed) | 1 | 00001010 |
8 bytes in total with UTF-8 encoding, as you can see in the ls -l output.
UTF-16
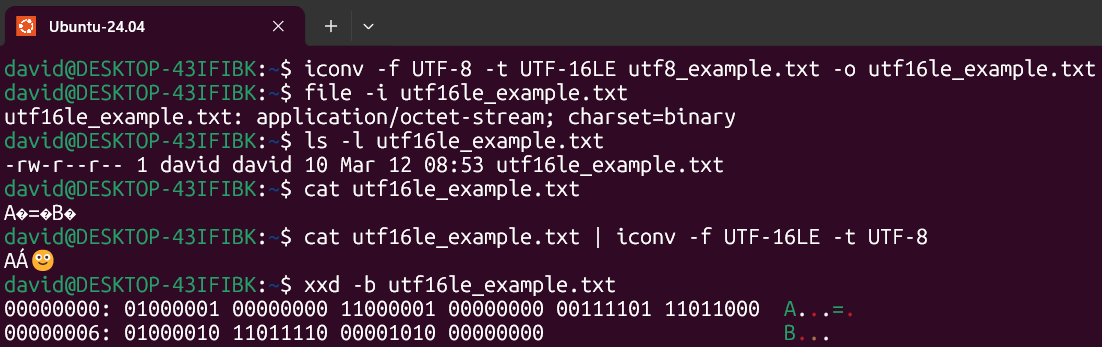
If we convert the file to UTF-16:
iconv -f UTF-8 -t UTF-16LE utf8_example.txt -o utf16le_example.txtWe need to reconvert the encoding to UTF-8 in order to print it on the screen.
cat utf16le_example.txt | iconv -f UTF-16LE -t UTF-8If we take a look at the binary data:
| Character | Bytes | Binary Representation |
|---|---|---|
| A | 2 | 01000001 00000000 |
| Á | 2 | 11000001 00000000 |
| 🙂 | 4 | 00111101 11011000 01000010 11011110 |
| LF (Line Feed) | 2 | 00001010 00000000 |
10 bytes in total with UTF-16 encoding.
UTF-32
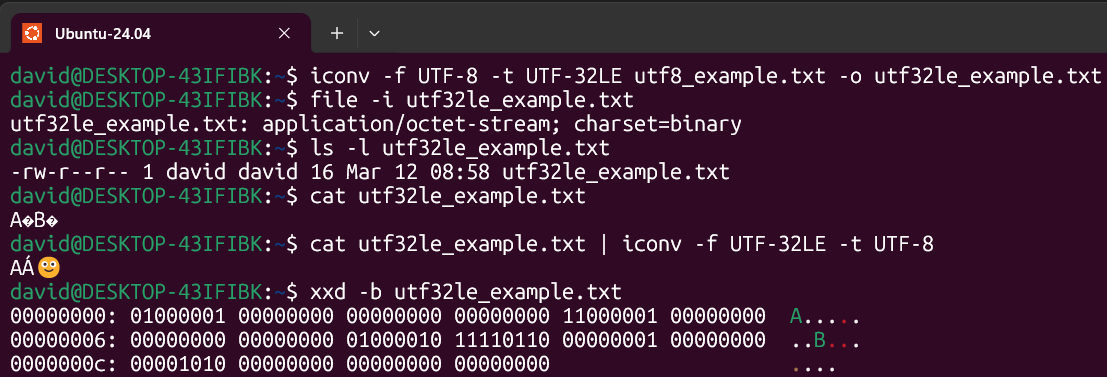
If we do the same and examine the binary data:
| Character | Bytes | Binary Representation |
|---|---|---|
| A | 4 | 01000001 00000000 00000000 00000000 |
| Á | 4 | 11000001 00000000 00000000 00000000 |
| 🙂 | 4 | 01000010 11110110 00000001 00000000 |
| LF (Line Feed) | 4 | 00001010 00000000 00000000 00000000 |
16 bytes in total with UTF-32 encoding.
Conclusion
- Notice that despite being the same Unicode Code Point, depending on the UTF encoding, the byte representation can vary, requiring more or fewer bytes to represent the same character. (The file size depends on the encoding).
- Notice that the capacity to represent new symbols, like new emojis, depends on the Unicode version, not the UTF encoding.
- UTF-8 is the most flexible and memory-efficient since it uses 1 byte for ASCII Code Points, which is the most common in most situations (for Latin-based languages), and up to 4 bytes for more complex characters.
- Measuring the size of a string or accessing a specific character can be inefficient in UTF-8 because each character has a variable size in bytes.
- UTF-16 would be the most efficient for other languages, such as Asian languages, as it handles symbols outside the ASCII range. UTF-16 requires conversion to ASCII because, despite using 2 bytes, it uses different bits than ASCII.
- UTF-32 requires the most memory of all, although size calculations and access are the most efficient since it has a fixed length, simplifying decoding.
Extra Knowledge 👀
Unicode Code Point to Bits
Not all bits are required to be part of the Code Point representation. For example, the Euro Sign € is the Code Point U+20AC or U+0020AC. 0020AC hexadecimal in binary is 00100000 10101100 (2 bytes), but the representation in UTF-8 is 3 bytes: 11100010 10000010 10101100.
UTF-8 encodes code points in one to four bytes, depending on the value of the code point. In the following table, the characters u to z are replaced by the bits of the code point, from the positions U+uvwxyz:
Code point ↔ UTF-8 conversion
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0yyyzzzz | |||
| U+0080 | U+07FF | 110xxxyy | 10yyzzzz | ||
| U+0800 | U+FFFF | 1110wwww | 10xxxxyy | 10yyzzzz | |
| U+010000 | U+10FFFF | 11110uvv | 10vvwwww | 10xxxxyy | 10yyzzzz |
The thing is that a default table with default values (1 byte) is used to generate the resulting 24 bits code:
| 11 | 10 | 00 | 10 | 11100010 |
| 10 | 00 | 00 | 10 | 10000010 |
| 10 | 10 | 11 | 00 | 10101100 |
| Number of bits | Binary codification |
|---|---|
| 8 | 0XXX XXXX |
| 16 | 110X XXXX 10XX XXXX |
| 24 | 1110 XXXX 10XX XXXX 10XX XXXX |
| 32 | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX |
LE/BE
LE (Little Endian) and BE (Big Endian) refer to the byte order used to store the multi-byte characters in the encoding.
Little Endian: The least significant byte (LSB) of the character is stored first (at the lower memory address). For example: 0xD800 => 0x00 0xD8.
Big Endian (BE): The most significant byte (MSB) is stored first. For example: 0xD800 => 0xD8 0x00.
BOM
Byte Order Mark (BOM) is a particular usage of the special Unicode character code, U+FEFF. Is a sequence of bytes at the beginning of a text file that indicates the byte order (endianness) and sometimes the character encoding used in the file.
- UTF-8: EF BB BF
- UTF-16 (Big Endian): FE FF
- UTF-16 (Little Endian): FF FE
- UTF-32 (Big Endian): 00 00 FE FF
- UTF-32 (Little Endian): FF FE 00 00
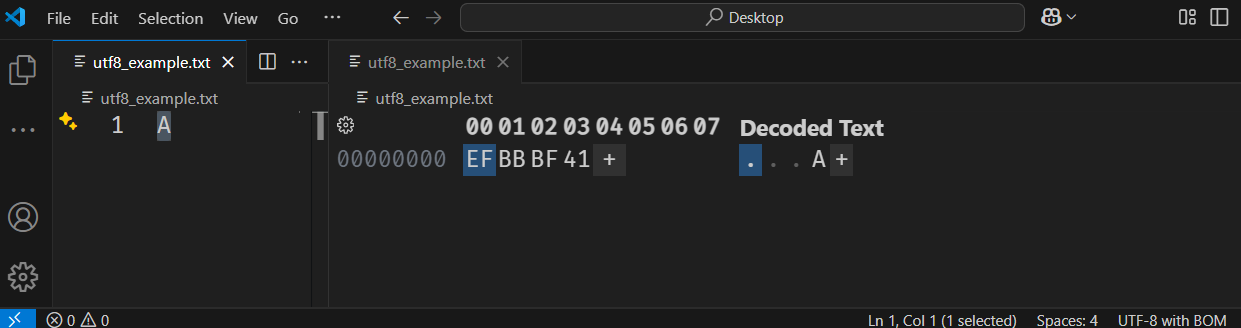
We can test this in Visual Studio Code, for example, using the Hex Editor. Open the file with the editor, then click on ‘Save with Encoding’ > ‘UTF-8 with BOM’. You will then see these bytes:”
End of String U+0000
The symbol Null, U+0000 is included in the C0 controls subblock of the Basic Latin block. Null can be used as a marker for the end of a string or an array of characters, especially in programming languages such as C and C++ (C-strings).
Programs and UIs like SQL Server Manager do not print this character. However, if the presence of null characters is enough, this could unexpectedly result in string-end representations for the UI, making it appear as though the string is truncated. Take a look to this with an example:
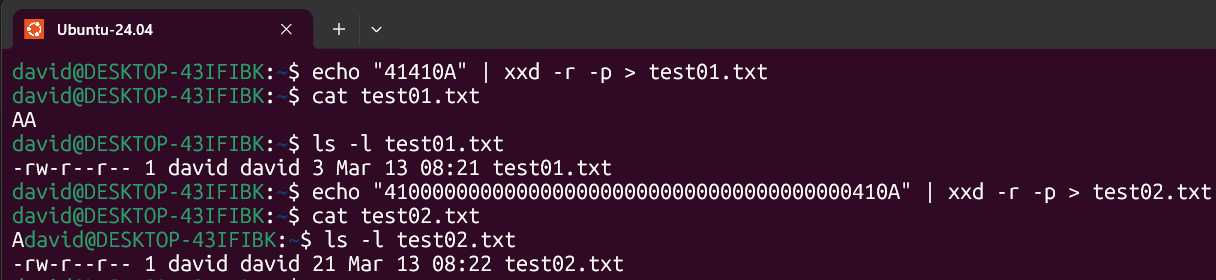
echo "41410A" | xxd -r -p > test01.txt
echo "410000000000000000000000000000000000000410A" | xxd -r -p > test02.txtAs you can see, test01.txt contains 3 bytes (A + A + LF), while test02.txt is 22 bytes. However, when printed, it only displays “A” because the x37 ceros are interpreted as string end.
Notice that this character is part of string escape sequences in many languages like .NET, but not in Java.